
An adaptive multiscale neural network architecture for representing large-scale scenes.
Video
Abstract
Neural representations have emerged as a new paradigm for applications in rendering, imaging, geometric modeling, and simulation. Compared to traditional representations such as meshes, point clouds, or volumes they can be flexibly incorporated into differentiable learning-based pipelines. While recent improvements to neural representations now make it possible to represent signals with fine details at moderate resolutions (e.g., for images and 3D shapes), adequately representing large-scale or complex scenes has proven a challenge. Current neural representations fail to accurately represent images at resolutions greater than a megapixel or 3D scenes with more than a few hundred thousand polygons. Here, we introduce a new hybrid implicit-explicit network architecture and training strategy that adaptively allocates resources during training and inference based on the local complexity of a signal of interest. Our approach uses a multiscale block-coordinate decomposition, similar to a quadtree or octree, that is optimized during training. The network architecture operates in two stages: using the bulk of the network parameters, a coordinate encoder generates a feature grid in a single forward pass. Then, hundreds or thousands of samples within each block can be efficiently evaluated using a lightweight feature decoder. With this hybrid implicit-explicit network architecture, we demonstrate the first experiments that fit gigapixel images to nearly 40 dB peak signal-to-noise ratio. Notably this represents an increase in scale of over 1000x compared to the resolution of previously demonstrated image-fitting experiments. Moreover, our approach is able to represent 3D shapes significantly faster and better than previous techniques; it reduces training times from days to hours or minutes and memory requirements by over an order of magnitude.
ACORN Framework
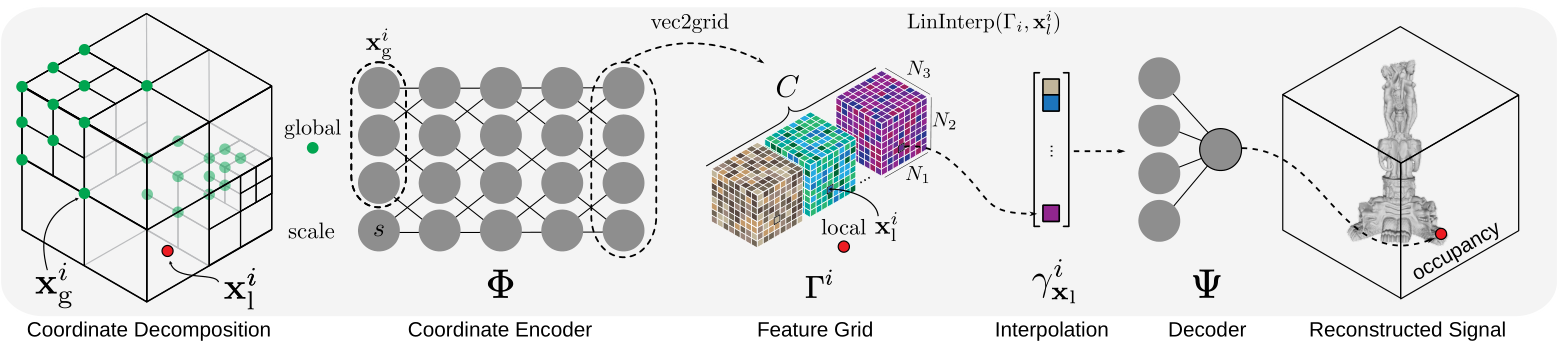
ACORN hybrid implicit–explicit architecture. Space is partitioned in blocks whose coordinates are fed to an encoder that produces a feature-grid. A set of local coordinates are used to address the feature grid, at any arbitrary position using linear intepolation, and yield a feature vector. The feature vector is the input of a lightweight neural network decoder that produces the signal of interest.
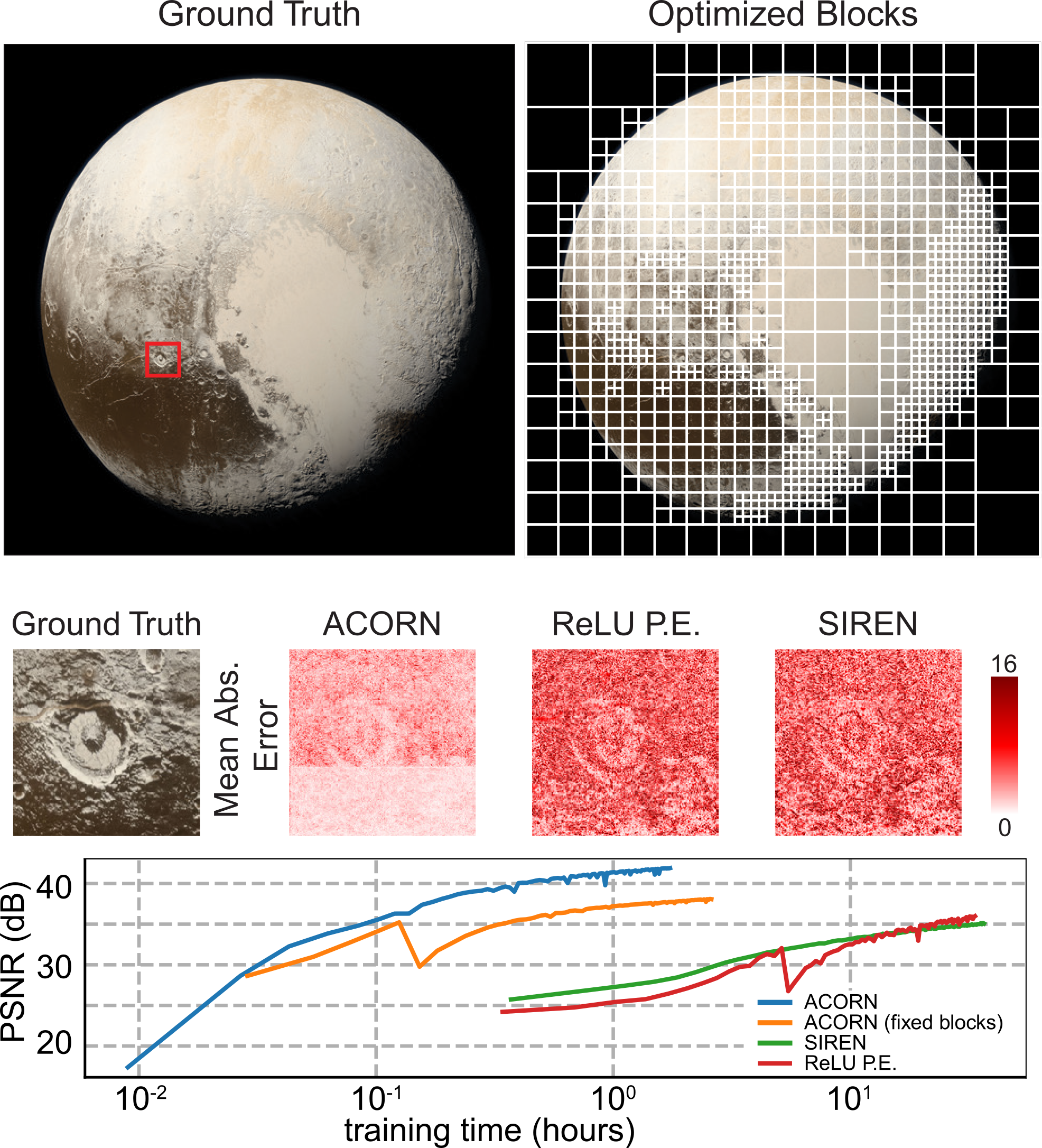
ACORN fits images better and faster. ACORN can fit this pluto image at a 4096×4096 resolution up to 30 dB in about 30 seconds, which is more than 2 orders of magnitude faster than conventional global implicit representations such as SIREN or MLPs using RELU with positional encoding.
Comparison of ACORN vs SIREN over 60s of fitting a 16 MP image.
Fitting a Gigapixel Image
An image with 1 billion pixels (gigapixel) rendered using ACORN.
Fitting High-Detail 3D Shapes
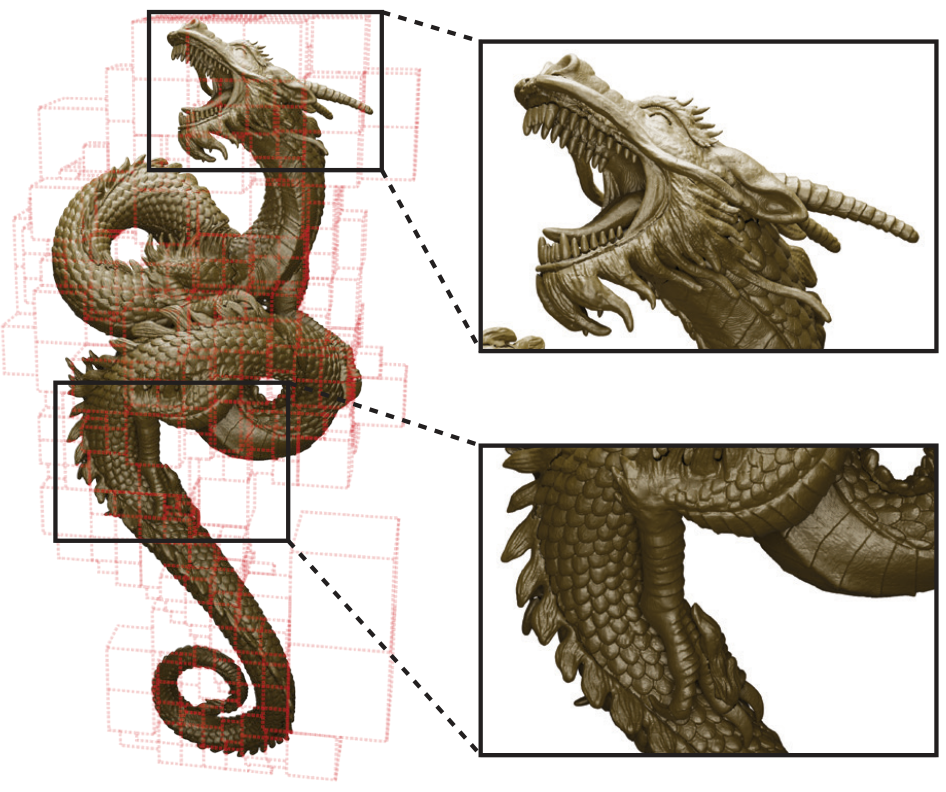
ACORN fitting a 3D model of a dragon and a visualization of the adaptive block decomposition.
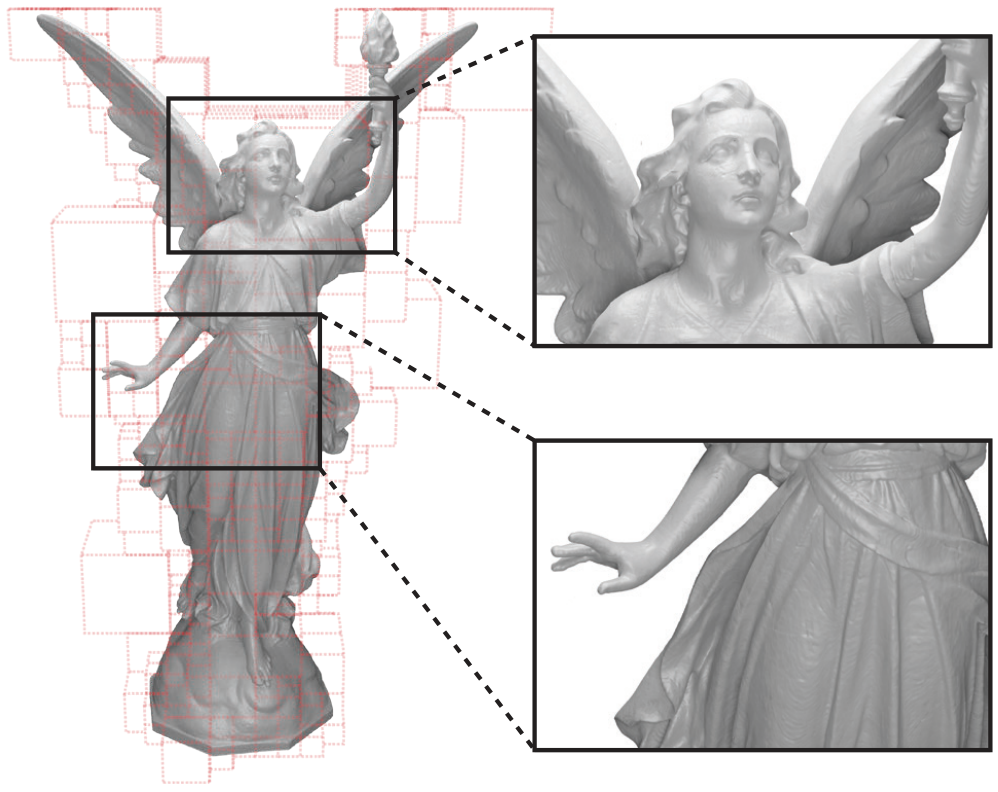
ACORN fitting a 3D model of Lucy (Stanford 3D model repository) and a visualization of the adaptive block decomposition.
Learned block decomposition of the Thai statue model.
Learned block decomposition of the engine model.
Acknowledgments
J.N.P. Martel was supported by a Swiss National Foundation (SNF) Fellowship (P2EZP2 181817). C.Z. Lin was supported by a David Cheriton Stanford Graduate Fellowship. G.W. was supported by an Okawa Research Grant, a Sloan Fellowship, and a PECASE by the ARO. Other funding for the project was provided by NSF (award numbers 1553333 and 1839974).
Citation
@article{martel2021acorn,
author = {Martel, Julien N.P. and Lindell, David B. and Lin, Connor Z. and Chan, Eric R. and Monteiro, Marco and Wetzstein, Gordon},
title = {ACORN: Adaptive Coordinate Networks for Neural Representation},
booktitle = {ACM Trans. Graph. (SIGGRAPH)},
year={2021}
}